Democratizing deep learning
Deep learning for embedded face recognition
In this article we present an approach on how to deploy the performance of state of the art deep learning CNN structures in an embedded device for the application of face recognition. The approach based on heterogeneous computing usage of CPU and GPU, provides a fast and low power solution that has the accuracy of a large VGG network thus making deep learning deployable in any embedded device.
")
Modern approaches based on deep neural network architectures are currently the state-of-the-art into learning efficient face representations. ( ©Frank Boston/Fotolia.com)
Besides the recent advances in image classification and retrieval, face recognition in-the-wild still remains a challenging task. This is due to the presence of significant variations in pose, illumination, inaccuracies in face detection and occlusions. Classical methods attempt to address these conditions by composing predefined functions on data, a procedure known as hand-crafted feature extraction. These methods can operate moderate in several scenarios, exhibit poor generalization performance. Today, Deep Convolutional Neural Networks (CNNs), are incorporating end-to-end learnable modules able to achieve robust feature representations. However, CNN based approaches developed by technology giants like Google, Baidu or others often require large amounts of data for training and are computationally intensive during evaluation, which makes them impractical or even prohibitive for embedded or time-critical applications. Driven by the application scenario and hardware platform, our novel system copes with these limitations by transferring the knowledge in terms of accuracy from large CNN networks into smaller ones able to operate in embedded and low-power platforms. In this work, we present Irida Labs approach for face recognition for videos and still images, running on embedded and low power mobile devices or cameras. Traditionally, face recognition aims to represent an input face image as a vector that will be used for recognition. Modern approaches based on deep neural network architectures are currently the state-of-the-art into learning efficient face representations, but when considered for embedded platforms they pose several major challenges, which we address here.
Video face recognition
For brevity, we focus on video face recognition running exclusively on embedded devices. We use CNN as a feature extraction layer and incorporate a proprietary meta-learning algorithm that allow us to separate the feature representation from the classification tasks. Our contribution is summarized in the following two axes.
– Training CNNs with limited data: Deep CNNs, scale well with the number of training samples, but collecting and annotating data is difficult and sometimes prohibitive in everyday scenarios. In order to cope with the limited amount of data, we are using two forms of transfer learning. First, we train a network trained on a different task, to learn a new task e.g. face recognition. Second, given a large model trained on a large face dataset one can distil the knowledge in a smaller one which as we show later, mimics the behavior of the large network and exhibits improved performance as compared to directly optimize on the task.
– Custom Classification Scheme: In embedded platforms, we need to add new users very fast (e.g. enroll one new person using a sample video or in real time). In order to achieve this, we implemented a meta-learning algorithm, which models the distribution of the users in a latent (low-dimensional) representation. For the final classification we incorporated the KL-Divergence.
Experimental Results
")
Multilayer CNN network commonly used in deep learning approaches. (Bild: Irida Labs)
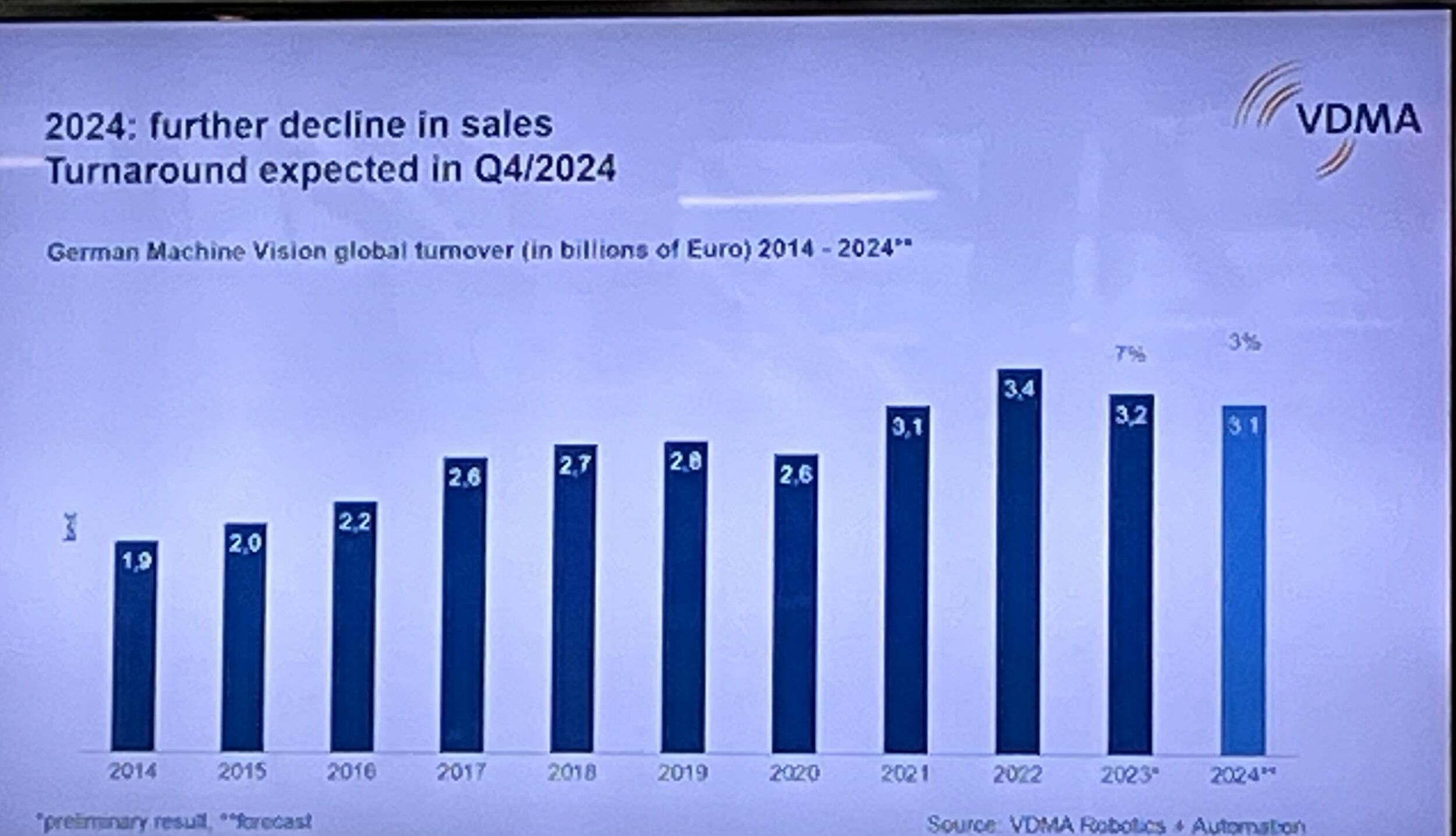
In our experiments we used a Squeezenet v1.1. CNN trained on VGG-face dataset via a custom distillation method as a feature extraction method and used our custom meta-learning algorithm in order to classify users. In order to evaluate our method, we used 50 persons from YTV dataset. Features extracted from CNN models were used to train our custom meta-classifier. Figure 3 presents the results for the original VGG-face, a SqueezeNet trained directly on VGG-face dataset and our Distilled VGG on SqueezeNet. These results demonstrate that for the scenario under consideration you can have the accuracy of a VGG network, designed for cloud and high performance computing.
Evaluation on embedded devices
")
Performance comparison between VGG-Face and the distilled Squeezenet. (Bild: Irida Labs)
Porting deep CNNs on embedded devices (e.g. android phones) is a very challenging task. In particular, the VGG-face requires 16GMACs (Giga Multiply-Accumulates per second) per image which is prohibitive. On the other hand, SqueezeNet requires 0.38GMACs per image making it a good candidate for embedded systems. Furthermore, current frameworks do not support or provide unoptimized ports for embedded phone-platforms. In Irida Labs we tackled this limitation and we exploited the advantages of Heterogeneous Programming in order to achieve very fast inference time (Snapdragon 820: 26msec/50fps/power consumption <150mW) for resolutions like FHD or higher.