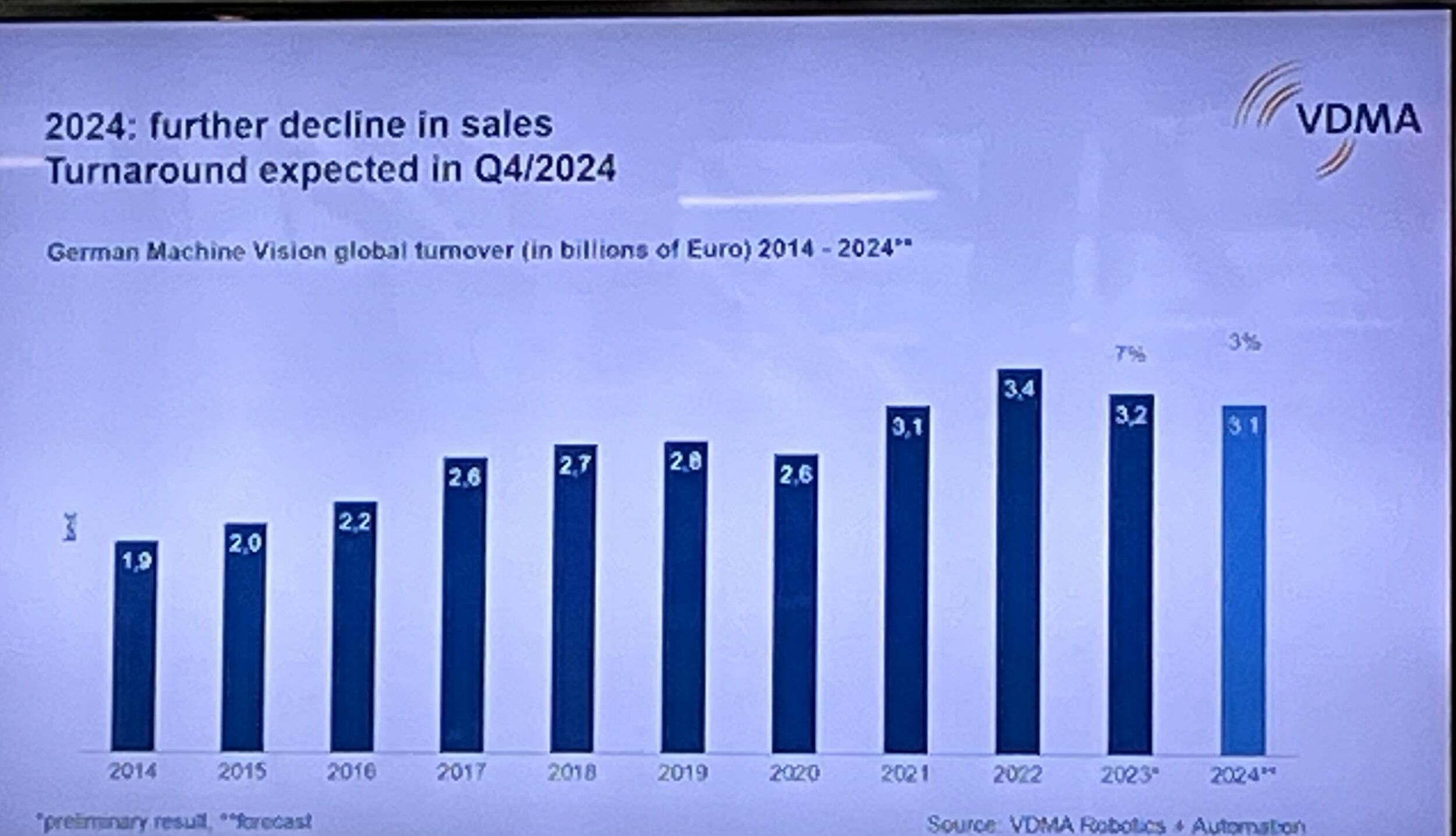
Inferenz Vergleich
VPU, GPU und FPGA im Vergleich für Deep-Learning-Inferenz
GPUs, FPGAs und Vision-Prozessoren (VPUs) verfügen über Vor- und Nachteile, die ein Systemkonzept beim Einstieg in eine Deep-Learning-Inferenz beeinflussen.
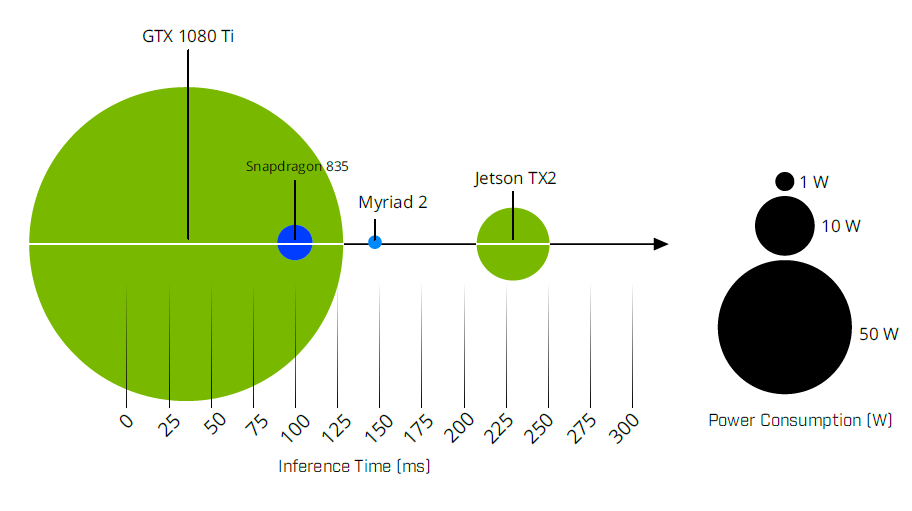
Bild 1 | Stromverbrauch vs. Einzelbild-Inferenzzeit im Vergleich einer GPU, SoC und VPU.
Bild unterer Teil: Relative Leistung einer GPU, FPGA und VPU zur Beschleunigung von Inferenz im Vergleich. (Bild: Flir Integrated Imaging Solutions Inc.)
GPU
GPUs sind aufgrund ihrer hochparalellisierten Verarbeitungsarchitektur optimal für die Beschleunigung von Deep Learning Inferenz geeignet. Nvidia hat in die Entwicklung von Tools für Deep Learning und Inferenz investiert, die auf Nvidias Cuda-Kernen (Compute Unified Device Architecture) ausgeführt werden können. Die GPU-Unterstützung von Google TensorFlow ist für Cuda-fähige GPUs von Nvidia bestimmt. Einige GPUs sind mit Tausenden von Prozessorkernen ausgestattet und eignen sich optimal für rechnerisch anspruchsvolle Aufgaben wie autonome Fahrzeuge oder Trainingsnetzwerke, die dem Einsatz mit weniger leistungsfähiger Hardware dienen. In der Regel verbrauchen GPUs viel Strom. Der RTX 2080 erfordert 225W, während der Jetson TX2 bis zu 15W verbraucht. GPUs sind zudem teuer, so kostet z.B. der RTX 2080 ca. 800USD.
FPGA
FPGAs sind in der industriellen Bildverarbeitung weit verbreitet. Sie vereinen die Flexibilität und Programmierbarkeit von Software, die auf einer CPU ausgeführt wird, mit der Geschwindigkeit und Energieeffizienz eines ASICs. Eine Intel Aria 10 FPGA-basierte PCIe Vision Accelerator-Karte verbraucht bis zu 60W Energie und ist für 1.500USD erhältlich. Ein Nachteil von FPGAs besteht darin, dass die FPGA-Programmierung spezielles Wissen und Erfahrung erfordert. Die Entwicklung neuronaler Netzwerke für FPGAs ist aufwändig. Zwar können Entwickler auf Tools von Drittanbietern zurückgreifen, um Aufgaben zu vereinfachen, doch die Tools sind meist teuer und können Anwender an geschlossene Ökosysteme proprietärer Technologien binden.