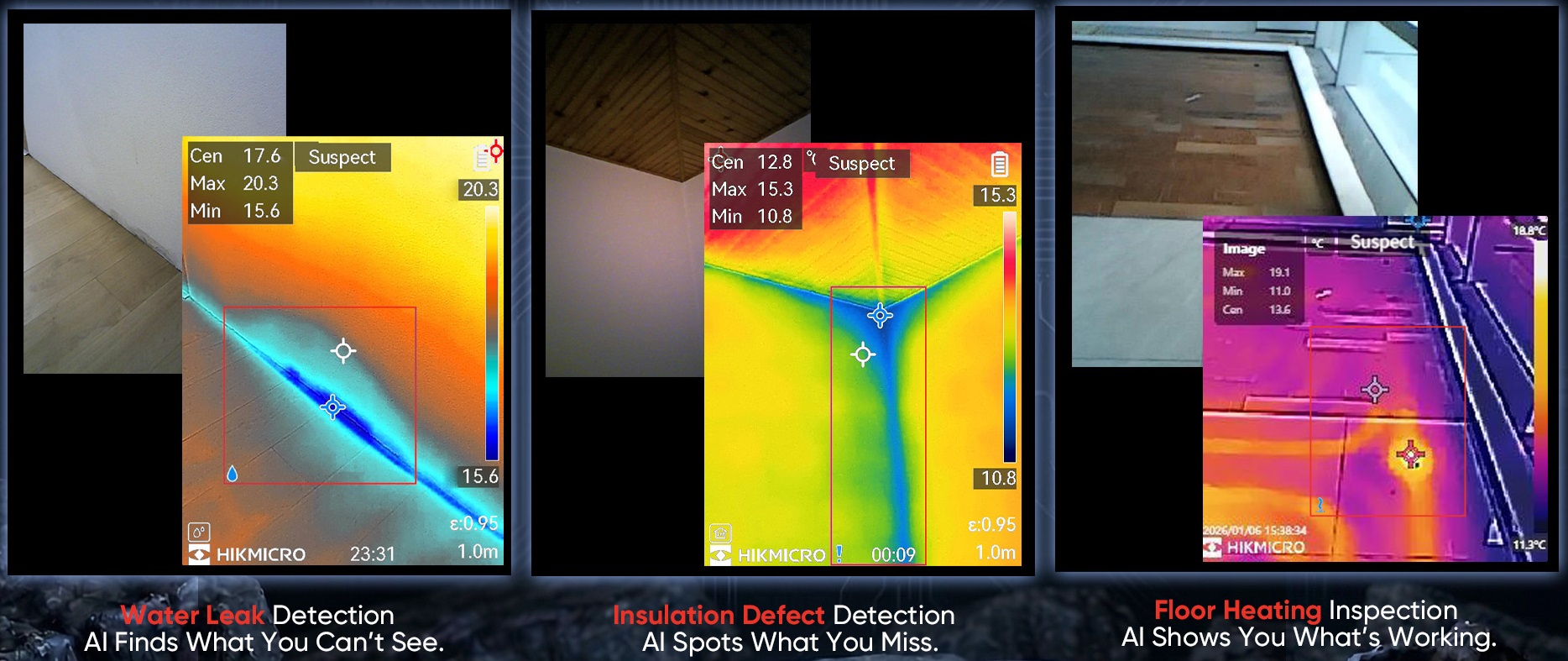
Event-Based Vision
Event-based vision is poised to take over from the frame-based approach used by traditional film, digital and mobile phone cameras in many machine-vision applications.
")
The mode of operation of state-of-the-art image sensors is useful for exactly one thing: photography, i.e. for taking an image of a still scene. Exposing an array of pixels for a defined amount of time to the light coming from such a scene is an adequate procedure for capturing its visual content. Such an image is a snapshot taken at one point in time and contains zero dynamic information. Nonetheless, this method of acquiring visual information is also used in practically all machine vision systems for capturing and understanding dynamic scenes. This approach is seemingly supported by the way movies are made for human observers. The observation that visual motion appears smooth and continuous if viewed above a certain frame rate is, however, more related to characteristics of the human eye and brain than to the quality of the acquisition and encoding of the visual information as a series of still images. As soon as change or motion is involved, which is the case for almost all machine vision applications, the paradigm of visual frame acquisition becomes fundamentally flawed. If a camera observes a dynamic scene, no matter where you set your frame rate to, it will always be wrong. As different parts of a scene usually have different dynamic contents, a single sampling rate governing the exposure of all pixels in an imaging array will naturally fail to yield adequate acquisition of these different scene dynamics present at the same time.
Individual Pixel’s Sampling Points in Time
An ´ideal´ image sensor samples parts of the scene that contain fast motion and changes at high sampling rates and slow changing parts at slow rates, all at the same time – with the sampling rate going to zero if nothing changes. Obviously, this will not work using one common single sampling rate, the frame rate, for all pixels of a sensor. Conversely, one wants to have as many sampling rates as there are pixel in the sensor – and let each pixel’s sampling rate adapt to the part of the scene it sees. To achieve this requires putting each individual pixel in control of adapting its own sampling rate to the visual input it receives. This is done by introducing into each pixel a circuit that reacts to relative changes of the amount of incident light, so defining the individual pixel’s sampling points in time. As a consequence, the entire image data sampling process is no longer governed by a fixed (artificial) timing source (the frame clock) but by the signal to be sampled itself, or more precisely by the variations over time of the signal in the amplitude domain. The output generated by such a camera is no longer a sequence of images but a time-continuous stream of individual pixel data, generated and transmitted conditionally, based on what is happening in the scene.